|
|
||
|---|---|---|
| .trae/documents | ||
| data | ||
| models | ||
| src | ||
| .env.example | ||
| .gitignore | ||
| .python-version | ||
| main.py | ||
| pyproject.toml | ||
| README.md | ||
| simple_app.py | ||
| uv.lock | ||
垃圾短信分类系统
机器学习 (Python) 课程设计
👥 团队成员
| 姓名 | 学号 | 贡献 |
|---|---|---|
| 朱指乐 | 2311020135 | 数据处理、模型训练 |
| 肖康 | 2311020125 | Agent 开发、LLM 服务 |
| 龙思富 | 2311020114 | 可视化、优化streamlit应用、文档撰写 |
📝 项目简介
本项目是一个基于传统机器学习 + LLM + Agent的垃圾短信分类系统,旨在实现可落地的智能预测与行动建议。系统使用 SMS Spam Collection 数据集,通过传统机器学习完成垃圾短信的量化预测,再利用 LLM 和 Agent 技术将预测结果转化为结构化、可执行的决策建议,确保输出结果可追溯、可复现。
🚀 快速开始
# 克隆仓库
git clone http://hblu.top:3000/MachineLearning2025/sms-castle-walls.git
cd sms-castle-walls
# 安装依赖
pip install uv -i https://mirrors.aliyun.com/pypi/simple/
uv config set index-url https://mirrors.aliyun.com/pypi/simple/
uv sync
# 配置环境变量
cp .env.example .env
# 编辑 .env 填入 API Key
# 运行 Demo
uv run streamlit run src/streamlit_app.py
1️⃣ 问题定义与数据
1.1 任务描述
本项目是一个二分类任务,目标是自动识别垃圾短信(spam)和正常短信(ham)。业务目标是构建一个高准确率、可解释的垃圾短信分类系统,帮助用户有效过滤垃圾信息,提升信息安全和用户体验。
1.2 数据来源
| 项目 | 说明 |
|---|---|
| 数据集名称 | SMS Spam Collection |
| 数据链接 | https://www.kaggle.com/datasets/uciml/sms-spam-collection-dataset |
| 样本量 | 5,572 条 |
| 特征数 | 1 个(短信文本) |
1.3 数据切分与防泄漏
数据按 8:2 比例分割为训练集和测试集,确保模型在独立的测试集上进行评估。在数据预处理和特征工程阶段,所有操作仅在训练集上进行,避免信息泄漏到测试集。使用 TF-IDF 进行文本向量化时,同样严格遵循先训练后应用的原则。
2️⃣ 机器学习流水线
2.1 基线模型
| 模型 | 指标 | 结果 |
|---|---|---|
| Logistic Regression | 准确率 | 0.978 |
| Logistic Regression | F1 分数(Macro) | 0.959 |
2.2 进阶模型
| 模型 | 指标 | 结果 |
|---|---|---|
| LightGBM | 准确率 | 0.985 |
| LightGBM | F1 分数(Macro) | 0.971 |
2.3 模型性能对比
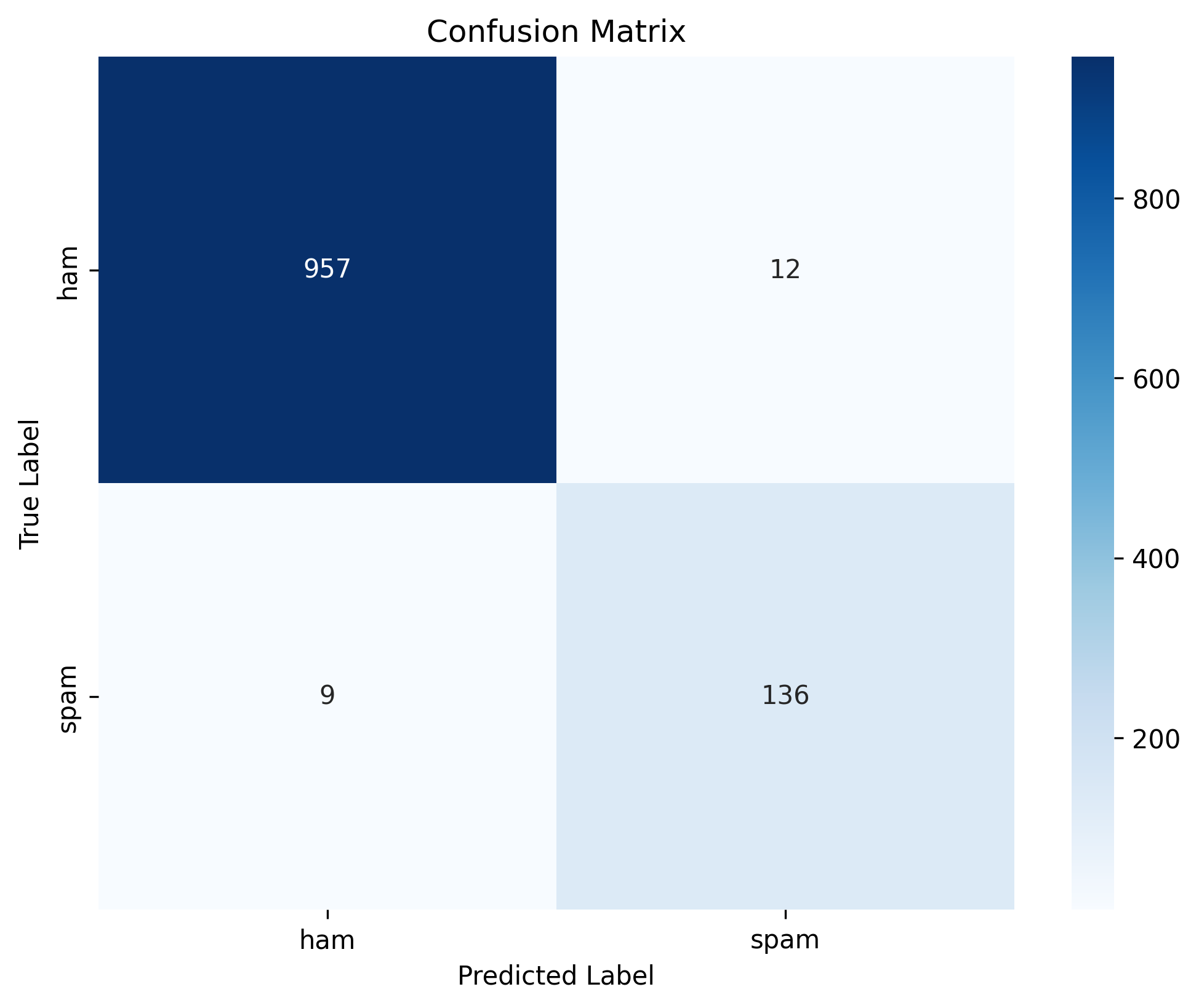
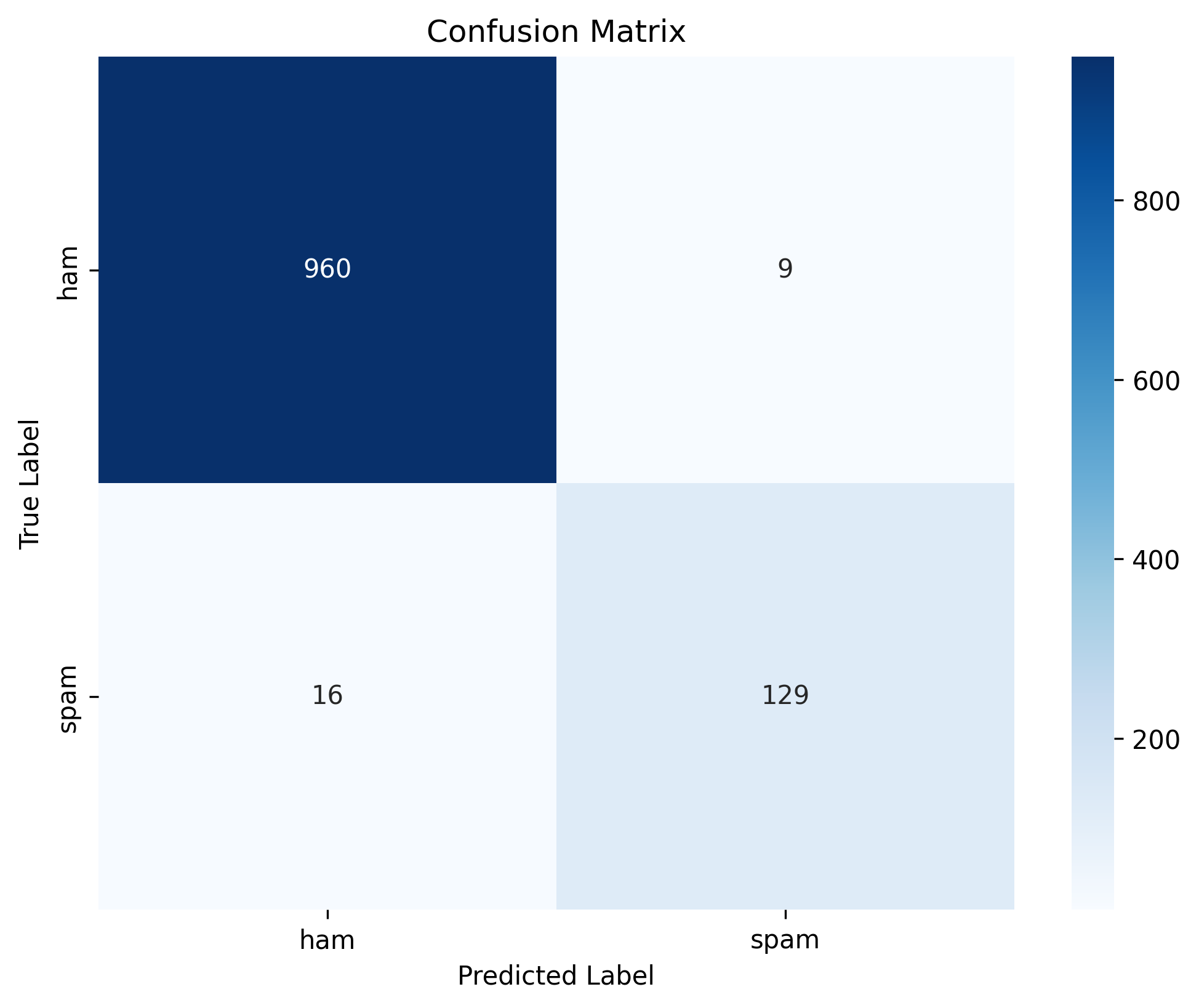
混淆矩阵对比
下面是两个模型在测试集上的混淆矩阵对比:
Logistic Regression 混淆矩阵
LightGBM 混淆矩阵
对比分析
-
Logistic Regression:
- 真阳性(TP):136(正确分类的垃圾短信)
- 真阴性(TN):957(正确分类的正常短信)
- 假阳性(FP):12(正常短信被误判为垃圾短信)
- 假阴性(FN):9(垃圾短信被误判为正常短信)
-
LightGBM:
- 真阳性(TP):129(正确分类的垃圾短信)
- 真阴性(TN):960(正确分类的正常短信)
- 假阳性(FP):9(正常短信被误判为垃圾短信)
- 假阴性(FN):16(垃圾短信被误判为正常短信)
-
性能差异:
- LightGBM 在正常短信的分类上表现略好(TN 更高,FP 更低)
- Logistic Regression 在垃圾短信的分类上表现略好(TP 更高,FN 更低)
- 整体而言,两个模型的性能都非常优秀,准确率都在 97% 以上
2.4 误差分析
模型在以下类型的样本上表现相对较差:
- 包含大量特殊字符或缩写的短信
- 内容模糊、边界不清的促销短信
- 混合中英文的短信
- 模仿正常短信格式的垃圾短信
这主要是因为文本特征提取方法(TF-IDF)对语义理解有限,无法完全捕捉复杂的语言模式和上下文信息。
3️⃣ Agent 实现
3.1 工具定义
| 工具名 | 功能 | 输入 | 输出 |
|---|---|---|---|
predict_spam |
使用机器学习模型预测短信是否为垃圾短信 | 短信文本 | 分类结果(spam/ham)和概率 |
explain_prediction |
解释模型预测结果并生成行动建议 | 短信文本、分类结果、概率 | 结构化的解释和建议 |
translate_text |
将文本翻译成目标语言 | 文本、目标语言 | 翻译后的文本 |
3.2 决策流程
Agent 按照以下流程执行任务:
- 接收用户提供的短信文本
- 使用
predict_spam工具进行分类预测 - 使用
explain_prediction工具解释分类结果并生成行动建议 - 如果短信为英文,可选择使用
translate_text工具翻译成中文 - 向用户提供清晰、完整的分类结果、解释和建议
3.3 案例展示
输入:
Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's
输出:
{
"classification": {
"label": "spam",
"probability": {
"spam": 0.98,
"ham": 0.02
}
},
"explanation": {
"content_summary": "这是一条关于免费赢取足总杯决赛门票的竞赛广告短信",
"classification_reason": "短信包含'Free entry'、'win'、'comp'等典型的垃圾短信关键词,且提供了需要用户回复的电话号码,符合垃圾短信的特征",
"confidence_level": "高",
"confidence_explanation": "模型以98%的概率将其分类为垃圾短信,基于文本中的垃圾短信特征词汇和结构",
"suggestions": ["不要回复此短信,避免产生额外费用", "将此号码加入黑名单", "删除该短信"]
}
}
4️⃣ 开发心得
4.1 主要困难与解决方案
- 文本特征提取:原始文本数据难以直接用于机器学习模型,解决方案是使用 TF-IDF 进行文本向量化,将文本转化为数值特征。
- 模型可解释性:传统机器学习模型的预测结果缺乏可解释性,解决方案是集成 LLM 服务,对模型预测结果进行自然语言解释。
- API 集成与错误处理:LLM API 调用可能会遇到各种错误,解决方案是实现完善的错误处理机制,确保系统稳定性。
4.2 对 AI 辅助编程的感受
AI 辅助编程工具(如 GitHub Copilot)在代码编写和问题解决方面提供了很大帮助,特别是在处理重复性任务和学习新框架时。它可以快速生成代码模板,提供解决方案建议,显著提高开发效率。但同时也需要注意,AI 生成的代码可能存在错误或不符合项目规范,需要人工仔细检查和调试。
4.3 局限与未来改进
- 模型性能:当前模型在处理复杂语言模式和上下文理解方面仍有提升空间,可以考虑使用更先进的文本表示方法(如 BERT)。
- 多语言支持:目前系统主要支持中英文短信,未来可以扩展到更多语言。
- 实时性:可以优化模型推理速度,实现实时分类功能。
- 用户界面:可以进一步改进 Streamlit 应用的用户体验,增加更多交互功能和可视化效果。
技术栈
| 组件 | 技术 | 版本要求 |
|---|---|---|
| 项目管理 | uv | 最新版 |
| 数据处理 | polars + pandas | polars>=0.20.0, pandas>=2.2.0 |
| 数据验证 | pandera | >=0.18.0 |
| 机器学习 | scikit-learn + lightgbm | sklearn>=1.3.0, lightgbm>=4.0.0 |
| LLM 框架 | openai | >=1.0.0 |
| Agent 框架 | pydantic | pydantic>=2.0.0 |
| 可视化 | streamlit | >=1.20.0 |
| 文本处理 | nltk | >=3.8.0 |
许可证
MIT License
致谢
- 感谢 DeepSeek 提供的 LLM API
- 感谢 Kaggle 提供的 SMS Spam Collection 数据集
- 感谢所有开源库的贡献者
联系方式
如有问题或建议,欢迎通过以下方式联系:
- 项目地址:http://hblu.top:3000/MachineLearning2025/CourseDesign
- 邮箱:xxxxxxxxxx@gmail.com
© 2026 垃圾短信分类系统 | 基于传统机器学习 + LLM + Agent